Introduction
The future of e-commerce is rooted in semantic understanding. This article explores how modern AI systems, driven by multimodal queries and advanced computer vision, depend on rich, descriptive image data—including high-quality alt text—to function. Readers will learn why structuring this data is no longer an optional compliance task, but the essential competitive strategy for achieving product discoverability and personalization.
The competitive landscape in digital commerce is evolving from a focus on visual presentation to semantic interpretation. Product images are no longer static display assets; they are dynamic, queryable, and highly structured databases. For e-commerce, the detailed information automatically extracted from an image is the new foundation for catalog management, personalization, and competitive strategy.
Retailers who heavily invest in high-quality image description data will establish a durable competitive advantage. This investment enables their AI systems to achieve superior product discoverability, deliver unmatched personalization, and secure the trust of the "AI shopper."
The shift to an AI-driven commerce landscape requires a strategic change in how digital retailers manage visual assets. Artificial Intelligence interprets e-commerce images by understanding their semantic meaning, style, and intricate context. This semantic understanding must move beyond basic object recognition to incorporate subjective concepts like trend and aesthetic appeal.
The future involves multimodal shopping experiences, seamlessly combining visual, text, and voice, such as a shopper pointing their camera at a sofa and asking their phone, "Find me a sofa like this but in navy blue" (Source). The retailers who build the infrastructure to understand and act on this complex, multimodal query will define the next generation of digital commerce.
Building the Linguistic Ground Truth
The essential layer of understanding for AI commerce is built upon high-quality, descriptive text data. This textual information, which includes alt text, structured product attributes, and rich contextual captions, serves as the linguistic “ground truth” that anchors multimodal AI models. This descriptive depth is what allows products to be mapped in vector space, enabling semantic search that understands user intent beyond simple keywords. By designing for accessibility with quality alt text, we are simultaneously structuring crucial data for machine readers.
In this new landscape, image descriptions are a core data layer that fuels AI discovery, personalization, and conversion. Without a rich, descriptive data layer, products are effectively silent and invisible to a massive, high-intent user base. Investment in this data infrastructure is an unavoidable competitive necessity that offers a quantifiable Return on Investment (ROI), notably by reducing return rates and boosting conversion.
Text as the Instructional Layer for AI
The major technical payoff of multimodal training is the model's zero-shot capability: the ability to correctly perform a task without having seen specific examples during training, relying instead on its pre-existing knowledge. This functionality relies on the integration of computer vision (visual features) and Natural Language Processing, or NLP, (human language) through structured textual input (Source).
Descriptive data is the textual input that empowers machines to comprehend and communicate visual content. Text transcends mere metadata; it becomes the active instruction the AI uses to classify, organize, and compare visual assets, thereby enabling advanced functionalities like zero-shot image classification and multimodal search.
For a retailer, a poorly written image description is a poor training sample. Conversely, high-quality, detailed descriptions are a critical mechanism for injecting qualitative, subjective context into the AI’s quantitative embedding space, which is crucial for hyper-personalization in areas like fashion and home goods.
Modern computer vision relies on robust, self-supervised learning models. E-commerce experiences must strategically leverage high-quality, proprietary descriptive data to inform the model. This process aligns the generalized semantic space with the precise language and taxonomy of the retailer’s product catalog, improving accuracy for specific use cases. For instance, while generalized models like OpenAI's Contrastive Language-Image Pre-Training CLIP are powerful, e-commerce requires highly specific domain knowledge, such as proprietary fabric names or niche product types, that generalized embeddings alone cannot provide for production environments (Source).
The Hierarchy of Image Description Data
The effectiveness of AI systems in digital commerce scales directly with the richness and structure of the input descriptive data, which exists in a hierarchy:
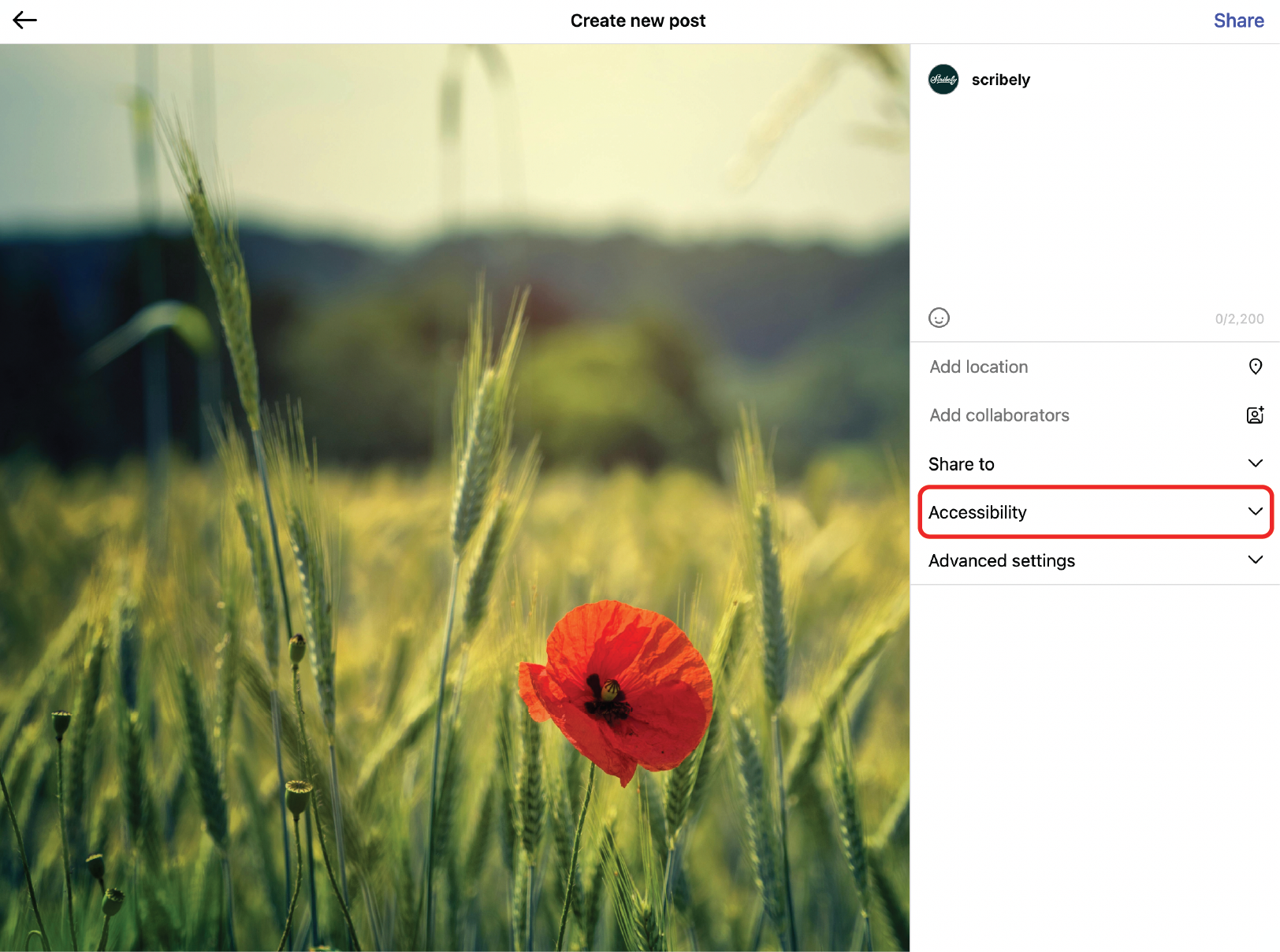
- Level 1: Alt Text (The Essential Grounding): The minimal, foundational text description originally designed for accessibility. For AI, it is the most basic, crucial text-image pair, establishing the baseline embedding and initial context for search engines.
- Level 2: Structured Product Attributes (The Categorical Engine): Highly structured metadata (e.g., "material: nylon," "feature: waterproof") that are extracted by AI for accurate filtering, SKU matching, and enhancing modern vector search capabilities (Source)
- Level 3: Rich Captions and Contextual Descriptions (The Semantic Layer): Detailed text segments conveying nuanced concepts like style, fit, texture, or brand ethos. This layer is key to teaching the AI subjective attributes and style preferences (Source).
The technological advances in multimodal AI, such as CLIP, have enabled improved image search and classification and opened the door for tools like DALL-E and Stable Diffusion. Since high-quality descriptive data improves the accuracy of the image-text embedding, it strategically increases a retailer’s latent capability to deploy future AI tools, such as automated visual merchandising or AI-generated lifestyle photography, transforming data quality into a form of latent intelligence.
Conclusion
High-quality descriptive data is a critical, often overlooked, strategic asset in modern AI Commerce. It functions as the interpreter, translating visual data into machine-understandable semantic embeddings that serve as the foundation for search, personalization, and conversion optimization. Descriptive text is the currency required to serve the AI shopper experience and is essential for organic discoverability and zero-shot recognition in modern multimodal AI.

Image Description
Image Description Goes Here
Check out Scribely's 2024 eCommerce Report
Gain valuable insights into the state of accessibility for online shoppers and discover untapped potential for your business.
Read the ReportCite this Post
If you found this guide helpful, feel free to share it with your team or link back to this page to help others understand the importance of website accessibility.